البرمجة بلغة بايثون (بناء محرك بحث)

مقدمة:
مرحباً بكم 👋 في مشروع بناء محرك بحث ( احد مشاريع منصة Code Khana ). في هذا المشروع سوف نقوم ببناء محرك بحث كامل يشبه محرك البحث كوكل عند انشائه في بداياته وهذا المشروع سيتكون من اربعة مشاريع مصغرة وهي:
- مشروع بناء خوارزمية عنكبوت الويب
- مشروع بناء فهرسة الروابط للمواقع الالكترونية
- مشروع خوارزمية تقييم الصفحات
- مشروع خوارزمية الترتيب السريع للصفحات
كل شيء سوف نقوم ببنائه في هذا المشروع سيكون بأستخدام اكواد بايثون البسيطه وبدون استخدام اي مكتبة خارجية وايضاً بدون استخدام الكلاس حيث سوف نقوم ببناء المشروع من خلال انشاء عدة وظائف كل وظيفه تقوم بدور معين ولكن في البداية سنتعلم بعض الاساسيات البسيطة عن لغة HTML والتي تستخدم في تصميم صفحات الويب وذلك لأننا سنتعامل في هذا المشروع مع مواقع الكترونية Web sites.
هذا المشروع عبارة عن محرك بحث بسيط يأخذ كلمه واحدة فقط ويبحث عنها في الصفحات ثم يرجع لك افضل الصفحات ذات العلاقة بالكلمة التي تبحث عنها من خلال ترتيب الروابط من الاكثر صلة الى الاقل صلة وهذا اكثر شيء يميز محرك البحث كوكل وهو النتائج ذات الصلة بالكلمة التي نبحث عنها وبأمكانك ايضاً تطوير هذا المشروع وجعله يأخذ اكثر من كلمة وبأمكانك تطويره اكثر واستخدام العديد من خوارزميات الذكاء الاصطناعي وجعل نتائجه اكثر دقه.
في هذا المشروع لن نستخدم البحث عن جميع الصفحات الموجودة على الانترنت لاننا لا نريد الزحف من خلال العناكب الى روابط المواقع الالكترونية على الانترنيت (لاسباب عديدة😐) بل سنقوم بأنشاء ستة صفحات بسيطة بداخلها محتوى وروابط الكترونية تؤدي الى الصفحات الاخرى وسنجمعها معاً في متغير سوف نسميه كاش cache بحيث يصبح كاش هو فضاء الانترنت بالنسبة لنا وبدل ان يحتوي على جميع صفحات الانترنت سوف نجعله يحتوي على ستة صفحات من صنعنا.

عناكب الويب (Web Crawler)
عناكب الويب وهي برامج مبنية لغرض البحث الاوتوماتيكي في فضاء الانترنت حيث تقوم هذه العناكب بالزحف الى صفحات الويب وتبحث عن الكلمات الرئيسية والمحتوى والروابط الموجودة في داخل صفحات الانترنت ثم ترجع الى محرك البحث هذه المعلومات.
ان الهدف من انشاء عناكب الويب هو الحصول على الروابط الالكترونية الموجودة في صفحات الانترنت ومن المعلوم ان صفحات الانترنت مبنية بلغة HTML ولرؤية مصدر اي صفحة على الانترنت فقط اضغط رايت كلك داخل الصفحة ثم اضغط على عرض مصدر الصفحة او view page source سيظهر لك مصدر الصفحة مكتوب بلغة HTML كما ستشاهد ان هناك العديد من الروابط داخل اي صفحة انترنت (قد تكون روابط لصفحات اخرى او روابط صور وفديوهات او غير ذلك).
الاساسيات البسيطة للغة HTML:
تكتب لغة HTML بأستخدام التاكات tags وهناك انواع مختلفة وادوار مختلفة لكل تاك فمثلاً لو كان لدينا الصفحة الالكترونية البسيطة التالية
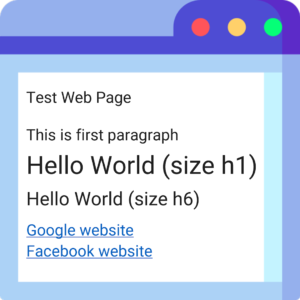
Test Web Page
This is first paragraph
Hello World (size h1)
Hello World (size h6)
Google website
Facebook Website
الصورة التالية توضح كود الـ HTML الذي تم استخدامه لبناء هذه الصفحة الالكترونية
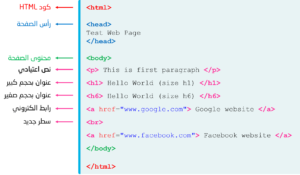
وكما هو واضح في الصورة ان صفحة الويب تم كتابتهة بأستخدام تاكات مختلفه وفي النقاط التالية سنوضح دور كل تاك في لغة HTML
- من اجل بناء صفحة ويب بلغة HTML نحتاج الى كتابة التاك < html > في بداية الصفحه ونغلقه بأستخدام التاك < html/ > وضع في بالك ان اغلب تاكات لغة HTML تحتوي على جزئين فتح واغلاق بأستخدام علامة /
- عادة في اكثر صفحات الويب يكون هناك رأس للصفحة يعرف بأسم head ومن اجل كتابة رأس الصفح نحتاج الى استخدام التاك < head > ثم نكتب رأس الصفحة ثم نغلق رأس الصفحة بأستخدام التاك < head/ >
- اهم شيء في صفحة الويب هو محتوى الصفحه وفي لغة HTML يبدأ محتوى الصفحة بالتاك < body > ثم يتم كتابة محتوى الصفحة بأستخدام تاكات لغة HTML المختلفة ثم يتم غلق محتوى الصفحة باستخدام التاك < body/ >
- نستطيع كتابة اي نص اعتيادي في الصفحة بأستخدام التاك < p > ثم نكتب اي نص نريده ثم نغلق النص بأستخدام التاك < p/ >
- نستطيع كتابة اي عنوان داخل الصفحة بأستخدام التاك < h1 > وهناك احجام مختلفة للعناوين تبدأ بأكبر حجم وهو التاك < h1 > وتنتهي بأصغر حجم وهو التاك < h6 > ويتم غلق تاك العنوان بأستخدام التاك < h1/ >
- نستطيع البدء او كتابة سطر جديد بأستخدام التاك < br > وهذا التاك لا يوجد فيه غلق.
- والتاك الاهم بالنسبة لنا في هذا المشروع هو تاك الروابط الالكترونية ويبدء هذا التاك بـ a > ثم نكتب الرابط الالكتروني داخل المتغير <” “=href ثم نكتب النص الذي نريد اظهاره ثم نغلق التاك بأستخدام < a/ > وللتوضيح اكثر الصورة التالية توضح شكل التاك الخاص بالروابط الالكترونية.

والان لنبدأ العمل .. اول شيء سنفعله هو خزن كود صفحة الويب على شكل متغير نصي حتى يسهل علينا البحث في داخل هذا المتغير بأستخدام الوظائف والمثود المختلفة التي تستخدم مع النصوص حيث سنقوم في الكود التالي بخزن كود الـ HTML لصفحة الويب في المتغير page
|
1 |
page = '<html><head>Test Web Page</head><body><p>This is first paragraph</p><h1>Hello World (size h1)</h1><h6>Hello World (size h6)</h6><a href="www.google.com">Google website</a><br><a href="www.facebook.com">Facebook Website</a></body></html>' |
الفكرة الان هي البحث عن الرابط الالكتروني داخل صفحة الويب وبما ان صفحة الويب اصبحت عبارة عن متغير نصي اسمه page اذاً نستطيع استخدام المثود ()find للبحث عن اي نص في هذا المتغير ، وبما ان الرابط الالكتروني يبدأ بـ =a href> اذاً سنقوم بالبحث عنها في داخل المتغير page ثم سنقوم بخزن الناتج في متغير سوف نسميه بداية اللنك start_link حيث ستكون قيمة هذا المتغير هي اندكس بداية اللنك.
|
1 2 |
start_link = page.find('<a href=') start_link |
|
1 |
128 |
ثم سنقوم بعدها بالبحث عن علامة التنصيص ” التي يبدأ بها الرابط الالكتروني ولكن سنبدأ البحث عنها من بعد اندكس بداية اللنك start_link لانها تأتي بعده.
|
1 2 |
start_quote = page.find('"', start_link) start_quote |
|
1 |
136 |
ثم سنقوم بالبحث عن علامة التنصيص ” التي ينتهي بها الرابط الالكتروني ولكن هذه المرة سنبدأ البحث من بعد علامة التنصيص الاولى start_quote وسنقوم بخزنها في متغير سوف نسميه نهاية التنصيص end_quote
|
1 2 |
end_quote = page.find('"', start_quote + 1) end_quote |
|
1 |
151 |
واخيرأ سنقوم بأستخراج الرابط الالكتروني والذي يبدأ من بعد علامة التنصيص الاولى start_quote وينتهي بعلامة التنصيص الثانية end_quote وسنقوم بخزن الناتج في المتغير url
|
1 2 |
url = page[start_quote +1 : end_quote] print(url) |
|
1 |
www.google.com |
الان سنقوم بأنشاء وظيفة سوف نسميها ()get_next_target هذه الوظيفة ستقوم بنفس المهمة السابقة وهي ترجع لنا اول رابط url يتم العثور عليه في الصفحة بالاضافة الى انها ترجع لنا الاندكس الذي يأتي بعد هذا الرابط end_qoute لان هذا الشيء سيسهل علينا البحث عن الروابط الاخرى الموجودة في الصفحة وسنتعلم ذلك بعد قليل.
الوظيفة التي في الكود التالي ستقوم بالبحث عن عنوان اول رابط تعثر عليه وستقوم بأستخراجه وبالتالي وسترجع لنا قيميتن وهي الرابط url والاندكس end_qoute الذي يبدأ بعد الرابط من اجل البحث عن الرابط التالي في حال كانت هناك روابط اخرى في الصفحة وكما تعلمنا سابقاً ان مثود البحث ترجع لنا اندكس العنصر الذي نبحث عنه وفي حال لم يكن العنصر الذي نبحث عنه موجود سترجع لنا القيمة 1- يعني العنصر غير موجود وايضاً ضع في بالك ان الوظيفة الموجودة في الكود التالي في حال كانت الصفحة لاتحتوي على روابط سوف لن ترجع الوظيفة لنا اي رابط (None) بالاضافة الى انها سترجع لنا رقم الاندكس القادم هو صفر.
|
1 2 3 4 5 6 7 8 |
def get_next_target(page): start_link = page.find('<a href=') if start_link == -1: return None, 0 start_quote = page.find('"', start_link) end_quote = page.find('"', start_quote + 1) url = page[start_quote + 1:end_quote] return url, end_quote |
والان سنستخدم الوظيفة ()get_next_target مع صفحة الويب التي قمنا بخزنها في المتغير page للتأكد انها سترجع لنا قيمتين الاولى هي الرابط الالكتروني والثاني هي الاندكس الذي بعد الرابط.
|
1 |
get_next_target(page) |
|
1 |
('www.google.com', 151) |
ومن اجل الحصول على جميع الروابط الالكترونية الموجودة في صفحة الويب نحتاج الى ادخال الوظيفة ()get_next_target في لوب وهذا ما سنقوم به الان ، حيث سنقوم بصناعة وظيفة سوف نسميها الحصول على جميع الروابط ()get_all_links مهمتها العثور على جميع الروابط الموجودة في الصفحة من خلال ادخال الوظيفة السابقة في لوب يقوم كل مرة بأيجاد اول رابط يعثر عليه ثم يبدأ مرة اخرى بالبحث عن رابط اخر ولكن بالبدأ من الاندكس الذي يبدأ بعد الرابط السابق وسوف ننشئ قائمة فارغة اسمها links ثم سيعمل هذا اللوب بأستمرار مادام يوجد هناك روابط (True) وفي كل مرة يعمل فيها اللوب سيضيف الرابط الذي عثر عليه الى القائمة links ثم سيتوقف هذا اللوب (break) في حال لم يكن هناك روابط اخرى يعني بعد اضافة جميع الروابط في الصفحة الى القائمة links وبالتالي سوف ترجع لنا هذه الوظيفة قائمة تحتوي على جميع الروابط الموجودة في الصفحة.
|
1 2 3 4 5 6 7 8 9 10 |
def get_all_links(page): links = [] while True: url, endpos = get_next_target(page) if url: links.append(url) page = page[endpos:] else: break return links |
والان لو استخدمنا الوظيفة ()get_all_links مع صفحة الويب page سنجد انها ترجع النا قائمة تحتوي على جميع الروابط الالكترونية الموجودة في الصفحة.
|
1 |
get_all_links(page) |
|
1 |
['www.google.com', 'www.facebook.com'] |
الان سوف نقوم بتهيئة عنكبوت الويب الذي يقوم بالزحف على صفحة معينة تسمى (البذرة seed) والتي يتعامل معها كالبذرة او البداية التي ينطلق منها ثم يرجع لنا بجميع الروابط الموجودة في هذه الصفحة بالاضافة الى الروابط الموجودة في داخل الصفحات الاخرى الموجودة في داخله مثل الصفحة (سيد) هي الرئيسية يقوم بجمع جميع الروابط الموجودة فيها واحد الروابط الموجودة في الصفحة الرئيسية هو رابط صفحة اسمها المساعدة حيث يقوم عنكبوت الويب ايضا بجمع جميع الروابط الموجودة بداخل صفحة المساعدة ولو كانت المساعدة ايضا تحتوي على صفحات بداخلها سيزحف اليها ويقوم بجمع الروابط التي بداخلها ونفس العملية لباقي الروابط يعني يجمع الروابط من الالف الى الياء وليست مهمته فقط جمع الروابط الموجودة في الصفحة (سيد) بل حتى الروابط الموجودة في داخل الصفحات المتصلة بالصفحة (سيد) وسنوضح ذلك الان.
الوظيفة التالية هي عنكبوت ويب وكما ذكرنا سابقاً انه ياخذ رابط معين يعتبره كنقطة انطلاق ويبدأ بجمع الروابط ولكن في الانترنت الحقيقي يجب ان نضع عمق معين لهذه الروابط لان عدد الروابط كبير جداً ويجب ان نحدد الوظيفة بحدود معينة ولكننا هنا لن نعمل على الانترنت كما ذكرنا في بداية الدورة بل سوف نقوم بصناعة ستة مواقع الكترونية بسيطة وهي غير حقيقية والغرض منها هو الشرح والتوضيح فقط.
هذه المواقع الستة عبارة عن الصفحة الاولى تحتوي على ثلاث وصفات طعام عربي والصفحة الثانية هي صفحة الشيف علي والصفحة الثالثة صفحة الشيف خالد والصفحة الرابعة صفحة وصفة المقبلات العربية والصفحة الخامسة صفحة وصفة لحم البقر المشوي والصفحة السادسة صفحة وصفة الكباب هذه الستة صفحات هي الفضاء الذي سوف نعمل عليه وجميع هذه الصفحات مخزونة في متغير اسمه كاش cache علماً انه بأمكانك جعل محرك البحث يعمل على صفحات الانترنت لكن غرض هذا المشروع هو تعليمي وليس تجاري.

1- http://yyy.com//intro-to-python/prank/index.html
2- http://yyy.com//intro-to-python/prank/ali.html
3- http://yyy.com//intro-to-python/prank/khaled.html
4- http://yyy.com//intro-to-python/prank/arabic-appetizers.html
5- http://yyy.com//intro-to-python/prank/roast-beef.html
6- http://yyy.com//intro-to-python/prank/kebab.html
ملاحظة: المتغير cache هو فضاء الانترنت الخاص بنا في هذا المشروع وهذا المتغير سيكون عبارة عن قاموس او فهرس مفاتيحه هو الرابط الالكتروني للصفحه وقيمته هي كود الـ HTML للصفحه.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
cache = { 'http://yyy.com//intro-to-python/prank/index.html': """<html> <body> <h1>Ahmed's Cooking Algorithms</h1> <p> Here are my favorite recipies: <ul> <li> <a href="http://yyy.com//intro-to-python/prank/kebab.html">Kebab Recipe</a> <li> <a href="http://yyy.com//intro-to-python/prank/roast-beef.html">World's Best Roast Beef</a> <li> <a href="http://yyy.com//intro-to-python/prank/arabic-appetizers.html">Arabic Appetizers Recipe</a> </ul> For more expert opinions, check out the <a href="http://yyy.com//intro-to-python/prank/khaled.html">Khaled Chef</a> and <a href="http://yyy.com//intro-to-python/prank/ali.html">Ali Chef</a>. </body> </html> """, 'http://yyy.com//intro-to-python/prank/ali.html': """<html> <body> <h1>The Ali Chef</h1> <p> I learned everything I know from <a href="http://yyy.com//intro-to-python/prank/khaled.html">the Khaled Chef</a>. </p> <p> For great roast-beef, try <a href="http://yyy.com//intro-to-python/prank/roast-beef.html">this recipe</a>. </body> </html> """, 'http://yyy.com//intro-to-python/prank/khaled.html': """<html> <body> <h1>The Khaled Chef</h1> <p> This is the <a href="http://yyy.com//intro-to-python/prank/arabic-appetizers.html"> best Arabic Appetizers recipe! </a> </body> </html> """, 'http://yyy.com//intro-to-python/prank/arabic-appetizers.html': """<html> <body> <h1> Arabic Appetizers Recipe </h1> <p> <ol> <li> Open a can of garbonzo beans. <li> Crush them in a blender. <li> Add 3 tablesppons of tahini sauce. <li> Squeeze in one lemon. <li> Add salt, pepper, and buttercream frosting to taste. </ol> </body> </html> """, 'http://yyy.com//intro-to-python/prank/roast-beef.html': """<html> <body> <h1> Let the beef rest for at least half an hour then slice thinly for a tender roast beef dinner </h1> <p> <ol> <li> Kidnap the <a href="http://yyy.com//intro-to-python/prank/khaled.html">Khaled Chef</a>. <li> Force him to make Arabic Appetizers for you. </ol> </body> </html> """, 'http://yyy.com//intro-to-python/prank/kebab.html': """<html> <body> <h1> Kebab Recipe </h1> <p> <ol> <li> Go to the restaurant and buy a Shish Kebab. <li> Eat it. </ol> </body> </html> """, } |
وايضاً سوف ننشأ وظيفة اسمها ()get_page تأخذ رابط الصفحة كمدخل وترجع لنا محتوى الصفحة.
|
1 2 3 4 5 |
def get_page(url): if url in cache: return cache[url] else: return None |
وقبل ان ننشئ وظيفة عنكبوت الويب سوف نقوم بأنشاء وظيفه نحتاجها داخل عنكبوت الويب وهي وظيفة الاتحاد ()union هذه الوظيفة سيكون دورها هو القيام بعملية الاتحاد بين قائمتين وترجع لنا قائمة واحدة تحتوي على جميع العناصر ولكن بدون تكرار والفائدة من ذلك هو لتجنب الروابط المتكررة.
|
1 2 3 4 |
def union(a, b): for e in b: if e not in a: a.append(e) |
والان سوف ننشئ وظيفة عنكبوت الويب والتي سوف نسميها ()crawl_web مدخل هذه الوظيفة هي الصفحة الرئيسية (البذرة seed) وسنصنع قائمتين داخل هذه الوظيفة اول قائمة هي قائمة روابط الصفحات التي نريد الزحف اليها (لم يتم الزحف اليها بعد) وسنسميها tocrawl والقائمة الثانيه هي قائمة روابط الصفحات التي تم الزحف اليها crawled
في داخل هذه الوظيفة سوف نصنع while لوب يعمل مادام هناك صفحات لم يتم الزحف اليها ويقوم هذا اللوب اولاً بحذف رابط الصفحة من قائمة tocrawl لأنه بدأت عملية الزحف لهذه الصفحة ويساعدنا هذا اللوب ايضاً في تجنب الزحف مرة اخرى للصفحات التي تم زحف اليها سابقاً فمثلاً لو كان رابط الصفحة الرئيسية تم الزحف اليه وفي الصفحة الثالثه يوجد رابط يؤدي الى الصفحة الرئيسية في هذه الحاله لن يتم الزحف مرة اخرى للصفحة الرئيسية
ثم سنضع شرط اذا كانت الصفحة غير موجودة في قائمة الصفحات التي تم الزحف اليها crawled قم بأضافتها الى قائمة الصفحات التي تم الزحف اليها crawled
ايضاً سنستخدم الوظيفتين (()get_page)get_all_links من اجل استخراج جميع الروابط من داخل هذه الصفحة وسنستخدم ايضاً الوظيفة ()union من اجل تجنب الروابط المتكررة
وفي النهاية سنجعل وظيفة عنكبوت الويب ()crawl_web ترجع لنا قائمة بجميع الروابط التي تم الزحف اليها crawled
|
1 2 3 4 5 6 7 8 9 10 |
def crawl_web(seed): tocrawl=[seed] crawled=[] while tocrawl: # p --> page p=tocrawl.pop() if p not in crawled: union(tocrawl, get_all_links(get_page(p))) crawled.append(p) return crawled |
والان لنقم بتجربة الوظيفة ()crawl_web حيث سنجعل مدخل هذه الوظيفة هو الصفحة الرئيسية ثم سنقوم بأدخال هذه الوظيفة في لوب من اجل طباعة جميع الروابط التي سيتم الزحف اليها والعثور عليها.
|
1 2 |
for i in crawl_web('http://yyy.com//intro-to-python/prank/index.html'): print(i) |
|
1 2 3 4 5 6 |
http://yyy.com//intro-to-python/prank/index.html http://yyy.com//intro-to-python/prank/ali.html http://yyy.com//intro-to-python/prank/khaled.html http://yyy.com//intro-to-python/prank/arabic-appetizers.html http://yyy.com//intro-to-python/prank/roast-beef.html http://yyy.com//intro-to-python/prank/kebab.html |

بناء فهرس (محرك بحث بسيط)
Build index (A Simple Search Engine)
الان سوف نقوم بأنشاء فهرسة ومحرك بحث بسيط يعطي نتائج غير مرتبة حتى وان كانت غير ذات صلة وسنقوم بذلك من خلال انشاء ثلاث وظائف جديدة بالاضافة الى تعديل وظيفة عنكبوت الويب السابقة حيث دور هذه الوظائف ان تقوم بالبحث عن كلمة معينة (كلمة مفتاحية keyword) في صفحات الويب التي تم الزحف اليها وفهرستها من خلال الوظائف الجديدة ثم ترجع لنا قائمة تحتوي على روابط المواقع التي تحتوي على هذه الكلمة ومثال على ذلك سوف نقوم بالبحث عن كلمة مقبلات Appetizers وسنحصل على جميع روابط الصفحات التي تحتوي على هذه الكلمة بداخلها مع ملاحظة انه بأمكاننا البحث عن اي كلمة موجودة في هذه المواقع الستة وفي حال كانت الكلمة غير موجودة لن نحصل على اي رابط.
اول وظيفة سنقوم بأنشائها هي وظيفة البحث ()look_up هذه الوظيفة تأخذ مدخلين هما الفهرس index الذي سنقوم بانشائه بعد قليل والكلمة المفتاحية keyword التي نبحث عنها وترجع لنا هذه الوظيفة قائمة بروابط الصفحات التي تحتوي على هذه الكلمة.
ملاحظة: عناصر قائمة الفهرس index تحتوي على جزئين ، الجزء الاول 0 هو الكلمة المفتاحية keyword والجزء الثاني 1 يحتوي على قائمة بروابط الصفحات الالكترونية التي توجد في هذه الكلمة المفتاحية.
|
1 2 3 4 5 6 7 |
def look_up(index, keyword): f = [] for i in index: if i[0]==keyword: for j in i[1]: f.append(j) return f |
الوظيفة التالية هي وظيفة الاضافة الى الفهرس او تحديث الفهرس ()add_to_index هذه الوظيفة تأخذ ثلاث مدخلات وهي الفهرس index والرابط الالكتروني url والكلمة المفتاحية keyword ثم تقوم بأضافة الكلمة المفتاحية keyword وقائمة روابط الصفحات التي توجد فيها هذه الكلمة [url] الى الفهرس index حيث من خلال هذه الوظيفة سيتم تحديث الفهرس بالكلمات المفتاحية والروابط الالكترونية التي توجد فيها هذه الكلمات.
|
1 2 3 4 5 6 |
def add_to_index(index, url, keyword): for i in index: if keyword==i[0]: i[1].append(url) return index.append([keyword, [url]]) |
الوظيفة الثالثة هي وظيفة اضافة محتوى الصفحة الى الفهرس ()add_page_to_index هذه الوظيفة تأخذ ثلاث مدخلات وهي الفهرس index ورابط صفحة الويب url ومحتوى الصفحة content ثم تقوم هذه الوظيفة بتجزئة الجمل الموجودة في محتوى الصفحة بأستخدام المثود ()split وفائدة هذه المثود هو تجزئة جمل الصفحة وتحويلها الى قائمة عناصرها كلمات مفردة (قائمة بالكلمات الموجودة في صفحة الويب) وبعد ذلك يتم تحديث محتوى الفهرس index بأستخدام الوظيفة السابقة ()add_to_index
|
1 2 3 |
def add_page_to_index(index, url, content): for i in content.split(): add_to_index(index, url, i) |
واخيراً سنقوم بتحديث وظيفة عنكبوت الويب ()crawl_web حيث سنقوم بصناعة قائمة الفهرس index وايضاً سنقوم بأستخراج محتوى الصفحات بأستخدام الوظيفة ()get_page وسنخزن محتوى الصفحة في المتغير c
ثم سنقوم بتحديث قائمة الفهرس index بأستخدام الوظيفة ()add_page_to_index ثم سنجعل وظيفة عنكبوت الويب ترجع لنا قيمتين الاولى هي قائمة الصفحات التي تم الزحف اليها crawled والقيمة الثانيه هي الفهرس index
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def crawl_web(seed): tocrawl=[seed] crawled=[] index=[] while tocrawl: # p --> page p=tocrawl.pop() if p not in crawled: # c --> content c=get_page(p) add_page_to_index(index, p, c) union(tocrawl, get_all_links(c)) crawled.append(p) return crawled, index |
والان اصبح كلشيء جاهز وسنقوم في الكود التالي بالزحف على الصفحة الرئيسية بأستخدام عنكبوت الويب حيث ستقوم هذه الوظيفة بالزحف الى جميع الصفحات وبفضل هذه الوظيفة سنحصل على قائمة بالروابط التي تم الزحف اليها crawled وسنحصل على فهرس كامل index
|
1 |
crawled, index= crawl_web('http://yyy.com//intro-to-python/prank/index.html') |
هذه قائمة روابط الصفحات التي تم الزحف اليها
|
1 |
crawled |
|
1 2 3 4 5 6 |
['http://yyy.com//intro-to-python/prank/index.html', 'http://yyy.com//intro-to-python/prank/ali.html', 'http://yyy.com//intro-to-python/prank/khaled.html', 'http://yyy.com//intro-to-python/prank/arabic-appetizers.html', 'http://yyy.com//intro-to-python/prank/roast-beef.html', 'http://yyy.com//intro-to-python/prank/kebab.html'] |
وهذا هو الفهرس
|
1 |
index |
ملاحظة:
الفهرس الذي في الاعلى يحتاج الى بعض التحسينات مثل تحويل جميع الحروف الى صغيرة وذلك لأن كلمة مثل Recipe تختلف عن كلمة recipe وايضاً يحتاج الى فصل بعض تاكات لغة HTML المتصقة في بداية او نهاية الكلمات ويحتاج الى حذف جميع تاكات لغة الـ HTML وذلك لأنها ليست كلمات تهم الباحث وايضاً يحتاج الى تجاهل الكلمات الغير مهمة مثل الضمائر واسماء الاشارة وادوات التعريف ..The, it, and, I, Here, etc
لكننا لن نقوم بهذه التعديلات في هذا المشروع من اجل عدم تعقيد الامور وبأمكانك القيام بهذه التحسينات في حال كانت لديك الرغبة في تطوير هذا المشروع.
والان لنجرب البحث عن كلمة مقبلات Appetizers في الفهرس بأستخدام الوظيفة ()look_up وسنشاهد في الناتج روابط جميع الصفحات التي تحتوي على كلمة مقبلات.
|
1 2 |
for i in look_up(index,"Appetizers"): print(i) |
|
1 2 3 4 |
http://yyy.com//intro-to-python/prank/index.html http://yyy.com//intro-to-python/prank/khaled.html http://yyy.com//intro-to-python/prank/arabic-appetizers.html http://yyy.com//intro-to-python/prank/roast-beef.html |

استخدام القواميس:
استخدام القواميس او ما يعرف بـ هاش تيبلز hash tables يسرع عملية البحث في محرك البحث بشكل كبير جداً ولذلك انشأت القواميس في لغة بايثون حيث بأمكاننا صناعة فهرس بأستخدام الدكشنري (القاموس) ولان الدكشنري يأخذ مفتاح وقيمة هذا يمكننا من خزن الكلمة كمفتاح في الدكشنري وخزن قائمة الروابط الالكترونية التي توجد بداخلها هذه الكلمة كقيمة للدكشنري فيصبح لدينا جميع الكلمات مخزونة على شكل مفاتيح والقيم هي قوائم الروابط التي تحتوي على هذه الكلمات بداخلها، وللقيام بهذه المهمة قمنا بأنشاء دكشنري اسمه اندكس index في وظيفة عنكبوت الويب ()crawl_web وقمنا بأستخدامه لخزن الكلمات والروابط من خلال تعديل الوظائف الاخرى وكما موضح في الكود الذي في الاسفل، ومن اجل معرفة التعديلات الجديدة قمنا بتأشير التعديلات الجديدة بملاحظة تبدأ بكلمة جديد New
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def look_up(index, keyword): #f=[] if keyword in index:#New: Direct lookup, no need to iterate return index[keyword] return [] def add_to_index(index, url, keyword): if keyword in index: if url not in index[keyword]:#New: To get rid of redundant urls index[keyword].append(url) return index[keyword]=[url]#New: A new hash entry def add_page_to_index(index,url,content): for i in content.split(): add_to_index(index, url, i) def crawl_web(seed): tocrawl=[seed] crawled=[] index={}#New: Dictionary initialization while tocrawl: p=tocrawl.pop() if p not in crawled: c=get_page(p) add_page_to_index(index, p, c) union(tocrawl, get_all_links(c)) crawled.append(p) return crawled, index crawled, index = crawl_web('http://yyy.com//intro-to-python/prank/index.html') # Print all urls for i in look_up(index, "Khaled"):##Searching for the keyword "Khaled" print(i) |
|
1 2 |
http://yyy.com//intro-to-python/prank/ali.html http://yyy.com//intro-to-python/prank/khaled.html |

خوارزمية تقييم الصفحات
Pagerank algorithm
في الكود السابق عندما بحثنا عن كلمة مقبلات حصلنا في الناتج على ترتيب عشوائي للصفحات وكانت اهم صفحة بالنسبة لنا هي صفحة المقبلات العربية لكن تسلسلها كان قبل الاخير وايضا عندما بحثنا عن كلمة خالد حصلنا على نتيجتين وكانت النتيجة الاولى صفحة علي والنتيجة الاخيرة هي صفحة خالد وهذا غير منطقي فتخيل لو كنت تبحث على الانترنت وهناك ملايين المواقع فربما لو بحثت في محرك بحث لايستخدم خوارزمية الرتيب والتقييم سيعطيك المحرك الاف النتائج ليس لها صلة بالذي تبحث عنه ، وحلاً لهذه المشكلة تم ابتكار خوارزمية التقييم والترتيب.
خوارزمية تقييم وترتيب الصفحات هي خوارزمية استخدمتها شركة كوكل من اجل اعطاء الباحثين من خلال محرك البحث كوكل نتائج ذات صلة ونتائج دقيقة. فكرة تقييم الصفحات تعتمد على شعبية الصفحة فمثلاً صفحة ذات شعبية عالية يكون تقييمها اعلى من الصفحات الغير معروفة وتكون شعبية الصفحة اعلى كلما تمت الاشارة اليها في صفحات اخرى فمثلاً موقع جامعة هارفرد تقييمه اعلى من تقييم موقع اي جامعة محلية وذلك لأن موقع جامعة هارفرد تمت الاشارة اليه في عدد كبير جداً من المواقع الالكترونية الاخرى.
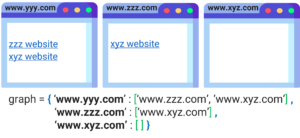
الرسم البياني التالي يوضح مجموعة صفحات الكترونية مترابطة فيما بينها ويوضح تقييم كل صفحة حسب شعبيتها.
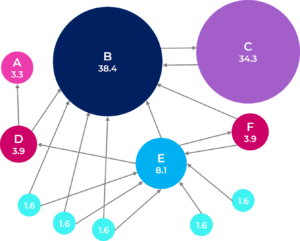
وايضاً ضع في بالك انه تزيد شعبية الصفحة اكثر اذا تمت الاشاره اليها من قبل مواقع ذات تقييم عالي فمثلاً لو تمت الاشارة الى صفحة معينة في موقع ذو تقييم عالي مثل جامعة اكسفورد هذا الشيء سيعطي هذه الصفحة تقييم عالي في حين لو تمت الاشارة الى نفس الصفحة في موقع محلي هذا الشيء سيزيد من شعبية هذه الصفحة قليلاً لكن لن يعطيها تقييم عالي.
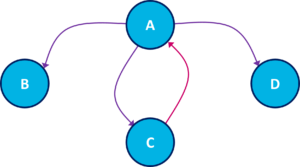
وحتى نستطيع تقييم الصفحات بشكل صحيح نحتاج اولاً الى استخدام ما يعرف بالـ كراف graph وهو ببساطة عبارة عن مخطط او رسم يوضح العلاقة بين الصفحات مثلاً لو كانت لدينا اربعة صفحات A, B, C, D الموضحة في الرسم الذي في الاسفل ، الكراف سيوضح لنا ان الصفحة A مرتبطة بالصفحات B, C, D وايضاً سيوضح لنا الاتجاه مثلاً تمت الاشارة في الصفحة A الى الصفحة B وتمت الاشارة في الصفحة A الى الصفحة C وبالعكس (يعني تمت الاشارة ايضاً في الصفحة C الى الصفحة A).

العلاقة بين الصفحات A, B, C, D بالامكان تمثيلها بأستخدام الكراف كما في الرسم التالي (الكراف عبارة عن عقد nodes مرتبطة فيما بينها والاسهم توضح اتجاه الارتباط بين العقد).
محرك البحث الذي سنقوم ببنائه سوف يقوم بتعقب الروابط الموجودة في الكراف ولكن نحتاج اولاً الى استخراج الكراف وسنقوم بذلك من خلال التعديل على عنكبوت الويب crawl_web الذي قمنا بصناعته سابقاً. عنكبوت الويب الذي قمنا بصناعته كان يرجع لنا الفهرس index اما الان فسنجعل عنكبوت الويب يرجع لنا الفهرس index والكراف graph والذي سنحتاجه لاحقاً في خوارزمية تقييم وترتيب الصفحات.
وفيما يلي الملاحظات والتعديلات التي سنقوم بها في الكود التالي:
الملاحظات:
- الكراف graph عبارة عن قاموس دكشنري جديد سنقوم بإنشائه في وظيفة عنكبوت الويب crawl_web مفتاح هذا الدكشنري سيكون عبارة عن رابط الكتروني لصفحة معينة وقيمة هذا الدكشنري ستكون عبارة عن قائمة تحتوي على جميع الروابط الالكترونية المرتبطة بهذه الصفحة والتي تعرف بأسم outlinks فمثلاً المفتاح هو الصفحة الرئيسية والقيمة عبارة عن قائمة تحتوي على روابط المواقع الالكترونية الموجودة في الصفحة الرئيسية ونفس الشيء مع باقي الصفحات.
- اي شيء جديد سنقوم بأضافته او تعديله بداخل وظيفة عنكبوت الويب سيكون مسبوق بكومنت NEW#
التعديلات:
- اول شي سنفعله هو انشاء دكشنري جديد فارغ سوف نسميه graph وسنقوم بخزن بيانات الكراف بداخله.
- سنقوم بصناعة متغير جديد سوف نسميه outlinks وسوف نخزن بداخله جميع الروابط الالكترونية الموجودة في محتوى الصفحة.
- بالنسبة للدكشنري graph سوف نجعل المفاتيح له page والتي هي الرابط الالكتروني للصفحة اما القيم فسنجعلها تساوي outlinks والتي هي عبارة عن قائمة تحتوي على جميع الراوبط الالكترونية الموجودة في داخل هذه الصفحة.
- واخيراً سوف نقوم بتعديل بسيط وهو اننا سنستخدم outlinks بدلاً من الوظيفة get_all_links لأننا قمنا بالخطوة الثانية بخزن هذه الوظيفة في المتغير outlinks
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Updated crawl_web function (returns index, graph of inlinks) def crawl_web(seed): tocrawl = [seed] crawled = [] #1-NEW: graph: <url page>, [list of pages it links to] graph = {} index = {} while tocrawl: page = tocrawl.pop() if page not in crawled: content = get_page(page) add_page_to_index(index, page, content) #2-NEW: get all links from content outlinks = get_all_links(content) #3-NEW: graph: page --> key & outlinks --> value graph[page] = outlinks #4-NEW: outlinks instead of get_all_links(content) union(tocrawl, outlinks) crawled.append(page) return index, graph |
نحن في هذا المشروع لدينا 6 صفحات مترابطة فيما بينها كما هو موضح في الرسم التالي
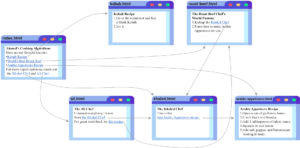
وحتى نتأكد اننا نعمل بصورة صحيحة سنقوم الان بتجربة وظيفة عنكبوت الويب بعد التحديث مع بذرة (seed) للأنطلاقه والزحف الى جميع الروابط ونقطة الانطلاق كما ذكرنا سابقاً ستكون الصفحة الرئيسية index ثم سنقوم بطباعة الكراف graph من اجل التأكد انه تم الزحف الى الصفحات الستة بالكامل وتم الحصول على الروابط الالكترونية التي ترتبط بها كل صفحة.
|
1 2 |
index, graph = crawl_web('http://yyy.com//intro-to-python/prank/index.html') graph |
|
1 2 3 4 5 6 7 8 9 10 11 |
{'http://yyy.com//intro-to-python/prank/index.html': ['http://yyy.com//intro-to-python/prank/kebab.html', 'http://yyy.com//intro-to-python/prank/roast-beef.html', 'http://yyy.com//intro-to-python/prank/arabic-appetizers.html', 'http://yyy.com//intro-to-python/prank/khaled.html', 'http://yyy.com//intro-to-python/prank/ali.html'], 'http://yyy.com//intro-to-python/prank/ali.html': ['http://yyy.com//intro-to-python/prank/khaled.html', 'http://yyy.com//intro-to-python/prank/roast-beef.html'], 'http://yyy.com//intro-to-python/prank/khaled.html': ['http://yyy.com//intro-to-python/prank/arabic-appetizers.html'], 'http://yyy.com//intro-to-python/prank/arabic-appetizers.html': [], 'http://yyy.com//intro-to-python/prank/roast-beef.html': ['http://yyy.com//intro-to-python/prank/khaled.html'], 'http://yyy.com//intro-to-python/prank/kebab.html': []} |
ايضاً بأستطاعتنا استخراج الروابط الالكترونية المرتبطة بصفحة معينة فمثلاً في الكود التالي سنقوم بطباعة الروابط الالكترونية المرتبطة بصفحة علي فقط.
|
1 |
print(graph['http://yyy.com//intro-to-python/prank/ali.html']) |
|
1 |
['http://yyy.com//intro-to-python/prank/khaled.html', 'http://yyy.com//intro-to-python/prank/roast-beef.html'] |
بعد ان اصبحت خوارزمية عنكبوت الويب جاهزة مازال هناك خوارزميتين نحتاج الى بنائهما وهما خوارزمية حساب التقييم وخوارزمية افضل ترتيب والمخطط التالي يوضح ذلك

وحتى نقوم ببناء خوارزمية الترتيب نحتاج الى استخدام معادلة رياضية من اجل حساب تقييم كل صفحة وهذه المعادلة الرياضية هي معادلة تقييم الصفحات التي توصلت اليها شركة كوكل في التسعينات من اجل تقييم الصفحات حسب شعبية كل صفحة ، وقد تكون المعادلة صعبة بعض الشيء بالنسبة للأشخاص الذين لديهم حساسية من الرياضيات ولذلك لن نتعمق في اشتقاقها وتفاصيلها الدقيقة.
الفكرة من هذه المعادلة اننا سنجعل تقييم الصفحة في البداية يساوي 1 تقسيم عدد الصفحات (number of pages)
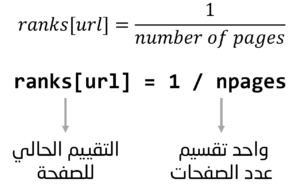
ولكن هذا التقييم مجرد تقييم ابتدائي للصفحة وهو غير دقيق ولذلك نحتاج الى تحديث هذا التقييم من خلال تكرار حساب تقييم الصفحة وسنقوم بذلك من خلال حساب التقييم الجديد للصفحة في كل خطوة زمنية جديدة (تكرار تحديث تقييم الصفحة سيعطينا تقييم اكثر دقة).
المعادلة الرياضية لعملية حساب التقييم الجديد للصفحة موضحة في الصورة التالية (في اسفل الصورة سوف نشرح هذه المعادلة).

معادلة حساب التقييم الجديد للصفحة مقسومة الى قسمين حيث القسم الاول الفائدة منه هو انه في حال كانت الصفحة لا تحتوي على روابط قادمة من صفحات اخرى (لاتوجد صفحة تشير اليها) سيكون شعبية هذه الصفحة 0 ويجب علينا تجنب هذه المشكلة لأنه لو اعطينا تقييم 0 للصفحات التي لا تحتوي على روابط قادمة سيكون من الصعب جداً على الصفحات الجديدة البدء والنجاح ، هذا القسم سيساعدنا في حساب احتمالية الوصول الى الصفحة وايضاً سيجعل الوصول ممكن الى بعض الصفحات حتى لو كانت لا توجد روابط تشير الى هذه الصفحات ، اما القسم الثاني من المعادلة فالهدف منه هو تحديث قيمة التقييم للصفحة من خلال تقسيم التقييم السابق للصفحة على عدد الروابط الخارجة outlinks لهذه الصفحة.
ملاحظة:
عنكبوت الويب عادة يبدأ بالزحف من صفحة عشوائية ويكون هناك مسار يتبعه للوصول الى كل الصفحات ولكن لو كان عدد الصفحات كبير هذا العنكبوت سيتعب في مكان معين وسيتوقف ثم سيختار صفحة عشوائية مجدداً وسيبدأ بالبحث مرة اخرى وستتكرر هذه الحالة كثيراً ولذلك نحتاج الى عامل اخماد damping والذي سيساعدنا في حل هذه المشكلة حيث سيحدد عامل الاخماد عدد المرات التي يختار فيها عنكبوت الويب صفحة عشوائية لأكمال عملية الزحف بدلاً من البدأ مجدداً (عامل الاخماد هو رقم اقل من واحد وبالنسبة لنا في هذا المشروع قمنا بتجربة عدة قيم وافضل قيمة كانت 0.8)
بناء خوارزمية حساب التقييم (مهم جداً):
بعد ان تعلمنا كيف يتم حساب تقييم الصفحة وكيف يتم تحديث هذا التقييم سوف نقوم الان بصناعة وظيفة لحساب تقييم الصفحات هذه الوظيفة سوف نسميها ()calculate_ranks ومدخل هذه الوظيفة سيكون graph وفي داخل هذه الوظيفة سنقوم في البداية بتعريف المتغيرات التي نحتاجها حيث سنقوم بإنشاء متغير عامل الاخماد d وسنجعل قيمته تساوي 0.8 وسوف ننشئ دكشنري فارغ سوف نسميه ranks وسنستخدمه لخزن تقييم الصفحات وسوف ننشئ متغير ثالث سوف نسميه npages وسوف نخزن فيه عدد الصفحات من خلال حساب طول الكراف.
|
1 2 3 4 |
def calculate_ranks(graph): d = 0.8 # damping factor ranks = {} # ranks dictionary npages = len(graph) # number of pages |
ثم سنقوم بحساب التقييمات الحالية ranks لكل صفحة وسنقوم بذلك من خلال لوب يمتد على طول كل الصفحات في الـ graph ثم نسطبق المعادلة الرياضية الاولى والتي هي 1 تقسيم عدد الصفحات.
|
1 2 |
for page in graph: ranks[page] = 1.0 / npages |
بعد ذلك سنقوم بحساب التقييمات الجديدة newranks حيث سنقوم بصناعة لوب يتكرر لـ 10 مرات (بامكانك التلاعب في عدد مرات التكرار ، وقد ذكرنا سابقاً ان عدد مرات تحديث التقييم للصفحة يؤثر على دقة حساب التقييم) وفي داخل هذا اللوب سنقوم بصناعة دكشنري فارغ نخزن يه التقييمات الجديدة newranks
ثم سنقوم بتقسيم المعادلة الرياضية لحساب التقييمات الجديدة الى قسمين حيث في القسم الاول سوف نصنع لوب يقوم بحساب احتمالية كل صفحة موجودة في الـ graph
|
1 2 3 4 |
for i in range(0, 10): newranks = {} for page in graph: newrank = (1 - d) / npages |
وفي القسم الثاني سنقوم بتحديث التقييم للصفحة من خلال تقسيم التقييم الحالي للصفحة على عدد الروابط الخارجة للصفحة وناتج التقسيم سيكون مضروب في عامل الاخماد ومجموع مع الجزء الاول من المعادلة، ثم سنقوم بتحديث الدكشنري newranks بالقيم الجديدة.
|
1 2 3 4 |
for p in graph: if page in graph[p]: newrank = newrank + d * (ranks[p] / len(graph[p])) newranks[page] = newrank |
واخيراً سنقوم بتحديث دكشنري التقييمات ranks وسنجعله يساوي newranks اي بمعنى انتقلنا من الخطوة الزمنية الحالية الى الخطوة الزمنية التالية ، ثم سنجعل وظيفة حساب التقييمات ترجع لنا التقييمات ranks
|
1 2 |
ranks = newranks return ranks |
والكود التالي يوضح كل ذلك
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Calculating ranks for a given graph -> for all the links in it def calculate_ranks(graph): d = 0.8 # damping factor ranks = {} # ranks dictionary npages = len(graph) # number of pages # Calculating the current ranks for page in graph: ranks[page] = 1.0 / npages # Calculating the new ranks for i in range(0, 10): newranks = {} # Part 1 for page in graph: newrank = (1 - d) / npages # Part 2 for p in graph: # Update by summing in the inlinks ranks if page in graph[p]: newrank = newrank + d * (ranks[p] / len(graph[p])) # Update the dictionary of newranks newranks[page] = newrank # Update ranks --> change the time step to the next time step ranks = newranks return ranks |
ولتجربة الوظيفة التي قمنا ببنائها سوف نقوم في الكود التالي بطباعة تقييم الصفحات من اجل التأكد اننا نعمل بشكل صحيح.
|
1 2 3 4 |
index, graph = crawl_web('http://yyy.com//intro-to-python/prank/index.html') ranks = calculate_ranks(graph) # print out ranks ranks |
|
1 2 3 4 5 6 |
{'http://yyy.com//intro-to-python/prank/index.html': 0.033333333333333326, 'http://yyy.com//intro-to-python/prank/ali.html': 0.038666666666666655, 'http://yyy.com//intro-to-python/prank/khaled.html': 0.09743999999999997, 'http://yyy.com//intro-to-python/prank/arabic-appetizers.html': 0.11661866666666663, 'http://yyy.com//intro-to-python/prank/roast-beef.html': 0.05413333333333332, 'http://yyy.com//intro-to-python/prank/kebab.html': 0.038666666666666655} |
لاحظ في الناتج ان اعلى تقييمين هما صفحة المقبلات العربية 0.11 وصفحة خالد 0.09 والسبب في ذلك هو ان صفحة المقبلات العربية تمت الاشارة اليها من قبل صفحة تقييمها عالي (صفحة خالد) وصفحة اخرى (الصفحة الرئيسية) اما سبب في تقييم صفحة خالد فهو ان صفحة خالد تمت الاشارة اليها من قبل ثلاث صفحات تقييمها متوسط.

خوارزمية الترتيب السريع للصفحات
Quicksort algorithm
بعد ان اكملنا بناء خوارزمية عنكبوت الويب وخوارزمية تقييم الصفحات تبقى لنا الان بناء خوارزمية الترتيب السريع للصفحات حيث سنتعلم الان كيف نقوم ببناء وظيفة تقوم بترتيب الصفحات تنازلياً حسب تقييم الصفحات والهدف من هذه الخوارزمية هو عندما يقوم الباحث بالبحث عن كلمة معينة سوف يحصل في الناتج على افضل الصفحات ذات الصلة بالكلمة (مرتبة من الاعلى تقييماً الى الاقل تقييماً).
خوارزمية الترتيب السريع Quicksort فكرتها بسيطة وذكية في نفس الوقت وحتى نفهم طريقة عمل هذه الخوارزمية وكيف تقوم بترتيب القيم لنفترض ان لدينا قائمة معينة ترتيب الارقام فيها عشوائي.
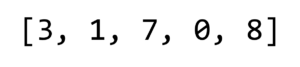
اول شيء ستفعله هذه الخوارزمية هو اختيار اي رقم من القائمة وهذا الرقم يسمى المحور pivot ولنفترض اننا اخترنا اول رقم في القائمة 3
هذا الرقم على اساسه سوف نقسم القيم الى نصفين (اكبر greater من الرقم المحوري واصغر smaller من الرقم المحوري) ثم سنضع الرقم المحوري في الوسط والقيم الاكبر منه سنضعها على اليمين والقيم الاصغر منه سنضعها على اليسار.
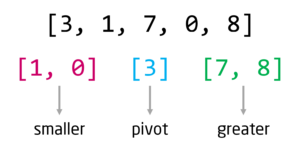
الان سنقوم بنفس الشيء للقائمة التي على اليسار حيث سنختار رقم محوري على اساسه نقسم القيم الصغيرة على اليسار والكبيرة على اليمين وسنفعل نفس الشيء للقائمة التي على جهة اليمين.
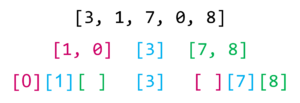
واخيراً سنعيد تجميع هذه القيم بقائمة واحدة وسنجد انه تم ترتيبها من الصغير الى الكبير.
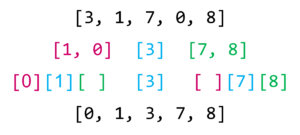
والان سنقوم بتحويل هذه الخوارزمية الى وظيفة سوف نسميها quicksort_pages هذه الوظيفة تأخذ مدخلين وهما روابط الصفحات pages وتقييم الصفحات ranks ثم سنقوم في داخل هذه الوظيفة بالخطوات التالية
- في البداية سوف نضع شرط if في حال كانت قائمة الصفحات فارغة لن نقوم بأي شيء
- ثم في الشرط الاخر else سوف ننفذ خوارزمية الترتيب السريع حيث سنقوم في البداية بصناعة ثلاثة قوائم
- القائمة الاولى هي قائمة الرقم المحوري pivot وسنجعل قيمته تساوي تقييم اول صفحة (التقييم المحوري)
- ثم سنصنع قائمتين worse لخزن التقييمات الاقل والاسوء من التقييم المحوري و better لخزن التقييمات الاعلى والافضل من التقييم المحوري
- ثم سنصنع لوب يمتد على طول الصفحات ولكن يبدأ من ثاني صفحة لأن اول صفحة للـ pivot
- ثم سنصنع شرطين الاول اذا كان التقييم اصغر من التقييم المحوري سوف نقوم بأضافته الى القائمة worse والشرط الاخر اذا كان التقييم اكبر من التقييم المحوري سوف نقوم بأضافته الى القائمة better
- واخيراً سنجعل الوظيفة ترجع لنا التالي (التقييمات الاكبر من التقييم المحورري + التقييم المحوري + التقييمات الاصغر من التقييم المحوري) من اجل ترتيب التقييمات تنازلياً
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Sorting in descending order def quicksort_pages(pages, ranks): if not pages or len(pages) <= 1: return pages else: pivot = ranks[pages[0]] worse = [] better = [] for page in pages[1:]: if ranks[page] <= pivot: worse.append(page) else: better.append(page) return quicksort_pages(better, ranks) + [pages[0]] + quicksort_pages(worse, ranks) |

البحث عن افضل النتائج
Look up best
اخر وظيفة سوف نقوم بصناعتها هي وظيفة ()look_up_best هذه الوظيفة فائدتها ستكون هي التالي:
- عندما يقوم الباحث بالبحث عن كلمة معينة سوف ترجع لنا هذه الوظيفة افضل روابط الصفحات ذات الصلة بهذه الكلمة (سوف يحصل الباحث على افضل النتائج).
- هذه الوظيفة تأخذ ثلاث مدخلات وهي الفهرس index وتقييم الصفحات ranks والكلمة المفتاحية keyword التي سيستخدمها الباحث.
- طريقة عمل هذه الوظيفة بسيط جداً حيث ستقوم هذه الوظيفة بالبحث عن الكلمة في الفهرس بأستخدام الوظيفة look_up التي صنعناها سابقاً وسنحصل في الناتج على روابط الصفحات التي تحتوي على هذه الكلمة ثم سنقوم بخزن هذه الروابط في المتغير pages ثم سنستخدم الوظيفة quicksort_pages لترتيب هذه الروابط من الافضل الى الاسوء حسب تقييمات الصفحات ranks
|
1 2 3 |
def ordered_search(index, ranks, keyword): pages = look_up(index, keyword) return quicksort_pages(pages, ranks) |
واخيراً اصبح محرك البحث جاهزاً ونستطيع الان تجربته والاطلاع على نتائجه..
في الكود التالي سنستخدم وظيفة عنكبوت الويب crawl_web للزحف الى الروابط ثم سنستخدم وظيفة حساب التقييمات calculate_ranks لحساب تقييمات الصفحات. واخيراً سنستخدم وظيفة ordered_search للبحث عن كلمة معينة (على سبيل المثال سوف نبحث عن كلمة مقبلات Appetizers).
|
1 2 3 4 5 |
index, graph = crawl_web('http://yyy.com//intro-to-python/prank/index.html') ranks = calculate_ranks(graph) for i in ordered_search(index, ranks, 'Appetizers'): print(i) |
|
1 2 3 4 |
http://yyy.com//intro-to-python/prank/arabic-appetizers.html http://yyy.com//intro-to-python/prank/khaled.html http://yyy.com//intro-to-python/prank/roast-beef.html http://yyy.com//intro-to-python/prank/index.html |
النتيجة التي حصلنا عليها مشابهة لنتائج محرك البحث كوكل في بداياته وهي نتائج دقيقه ومرضيه للباحث حيث حصلنا في الناتج على التالي:
- اول صفحة هي صفحة المقبلات العربية arabic appetizers وهذه النتيجة جداً دقيقة لأن هذه الصفحة ذات صلة عالية بكلمة مقبلات (هي الصفحة التي نبحث عنها بالاساس).
- ثاني صفحة هي صفحة الشيف خالد khaled وذلك لأنه تم ذكر كلمة مقبلات ففي هذه الصفحة بالاضافة الى ان تقييم هذه الصفحة عالي.
- ثالث صفحة هي صفحة لحم البقر المشوي roast beef وذلك لأنه تم ذكر كلمة المقبلات في هذه الصفحة.
- رابع صفحة هي الصفحة الرئيسية index وذلك لأنه تم ذكر كلمة المقبلات في هذه الصفحة
ملاحظة:
في لغة بايثون يوجد وظيفة اسمها ()input هذه الوظيفة تمكن المستخدم للبرنامج من ادخال قيمة معينة وخزنها في متغير. على سبيل المثال لو قمت بتنفيذ الكود التالي سوف تظهر لك خانة فارغة في الاسفل بأمكانك كتابة الكلمة التي تريد البحث عنها في هذه الخانة.
وللتجربة اكتب كلمة Khaled ثم اضغط انتر..
|
1 2 3 4 5 6 7 8 9 10 |
# input() function search_word = input('Enter What you want to search: ') results = ordered_search(index, ranks, search_word) try: for i in results: print(i) except: print('No result') |
|
1 2 3 |
Enter What you want to search: Khaled http://yyy.com//intro-to-python/prank/khaled.html http://yyy.com//intro-to-python/prank/ali.html |
الذي حصل في الكود السابق هو اننا استخدمنا الوظيفة input وجعلنا المستخدم هو من يدخل القيمة (على شكل نص) ثم تم خزن هذه القيمة في المتغير search_word ثم تم استخدام هذا المتغير مع الوظيفة ordered_search للبحث عن الكلمة التي قام المستخدم بأدخالها ، ثم قمنا بصناعة لوب بسيط يقوم بطباعة الروابط الالكترونية ذات الصلة بالكلمة التي تم ادخالها وفي حال لا يوجد اي رابط الكتروني سيتم طباعة No result
ملاحظة:
في الاعلى استخدمنا try وتعني حاول ، واستخدمنا except وتعني عدا ذلك حاول شيء اخر ، الفائدة من استخدامهما بدلاً من if & else هي ان try & except في حال كانت المحاولة خاطئة لن نحصل في الناتج على خطأ Error يوقف البرنامج.
النهاية:
انجاز عظيم! لقد تمنكا في النهاية من بناء محرك بحث ويب من الالف الى الياء مبني بأستخدام خوارزميات ذكية وقمنا ببناء هذا المحرك بالكامل بأستخدام اكواد بايثون البسيطة ودون الحاجة لأستخدام اي مكتبة خارجية
في النهاية شكر وتقدير للبروفيسور ديفيد إيفانز من جامعة فيرجينيا الامريكية لمساعدته في هذا المشروع.
كود المشروع (اضغط هنا)